什么是文字转语音?
文本转语音(也称为 TTS)是一种将书面文字转换为可听语音的技术。当无法或不方便阅读屏幕时,AI 语音生成器会与用户进行交流。文本转语音技术开辟了应用程序和信息的新用途,提高了无法阅读在屏幕上的文本的个人的可访问性。
在过去几十年间,文本转语音技术不断发展。深度学习可以生成非常自然的语音,包括音调、语速、发音和语调的变化。如今,计算机生成的语音用于多种应用场景,并且成为了用户界面中的标配。新闻阅读器、游戏、公共广播系统、电子学习、电话、物联网应用程序和设备以及个人助理只是起点。
文本转语音有哪些优势?
语音合成提高应用程序的可访问性,使用户无需紧盯屏幕就能够使用和理解信息。下面简要介绍了使用文本转语音技术的一些关键优势。
可访问性
文本转语音可满足各种沟通方式和偏好的需求,扩大了数字内容的受众范围。它提高了由于视力障碍、读写困难、年龄或其他健康问题而无法阅读的用户的访问能力。作为一种辅助技术,它提供��一种获取信息和确保包容性的替代方法。
高级学习
文本转语音可以应用于在线材料,以便进行在线学习。通过将视觉和音频演示相结合,可以提高理解力、回想度、词汇技能、动力和信心。该技术可以大声朗读数字文本,使语言学习者能够理解单词和短语的准确发音。听文本还可以巩固词汇记忆,并加强对句子结构的理解。
移动性和自由度
文本转语音可以将任何数字内容转化为多媒体体验。人们可以在旅途中或处理多项任务时收听新闻、博客文章甚至 PDF 文档。这种灵活性可以提高工作效率,因为用户无需动手即可使用内容。
参与度和用户体验
TTS 技术鼓励用户阅读长篇的文章、报告或书籍。用户能在更短的时间内获取更多文字内容,从而提高内容留存率。它可以改善应用程序指标,例如访问者数量和在网站上停留的时间。通过增强客户旅程,您可以提高转化率。
快速且经济实惠
云计算使文本转语音的实施变得快速而简单。云的规模经济也降低了集成成本。无需预付或支付最低月费即可开始使用。只需在用户访问该功能时付费。
文本转语音技术的应用场景有哪些?
使用语音进行通信的应用程序会日益普遍。借助文本到语音转换的解决方案,您的网站、移动应用程序、电子书、在线学习工具和在线文档都可以拥有自己的声音。我们在下面给出一些使用案例示例。
音频发布
出版商和内容所有者可以使用文本到语音转换功能以快速且成本低廉的方式将图书、文章以及书面材料转换成音频。您可以转换现有的书面文本,使其适合针对广泛的学习者群体的在线学习和培训应用场景。将您的内容转换为更有效且成本更低的格式,以多种语言推出。
客户服务
TTS 系统可以提高交互式呼叫中心的质量,并且支持通信应用程序。构建更好的聊天机器人和 AI 助手,在用户需要时为其大声朗读数字文本。它也是交互式响应机制和自动电话系统中的一项关键技术。将自动客户服务交互从单调的短语扩展到令人产生同理心并提高客户满意度的对话回复。
媒体与娱乐
TTS 技术可用于为视频、动画和交互式游戏生成画外音。它可以降低成本,并提高媒体前期制作和开发的效率。它还支持根据游戏或交互式应用程序中的玩家动作进行实时叙述和动态评论。您还可以使用文本转语音工具在虚拟现实(VR)环境中提供沉浸式音频内容。
医疗保健
医疗保健领域的 TTS 技术开辟了与患者的沟通渠道,并解决了医疗保健专业人员短缺的问题。具有语音接口的生成式人工智能应用程序可以解释患者的咨询和意图、对患者进行分类并以自然的声音进行回应。它们可以执行从预约到支持治疗管理和药物提醒的所有工作,而无需强迫患者阅读屏幕内容。
文本转语音是如何工作的?
文本转语音系统利用强大的人工智能(AI)和机器学习(ML)模型,从文本生成语音。这些模型在深度神经网络(像人脑一样相互连接并协同工作的计算节点)上运行。深度神经网络使用各种语言、口音、音调和音量的语音数据进行训练。在训练期间,需要将音频片段及其对应的转录文本提供给 AI 模型。该模型可识别书面文本和语音文本之间的相互关系和模式。它利用这些知识来分析新文本并将其转换为声音。
此流程的工作原理如下所示。
将文本转换为时间对齐的特征
神经网络首先获取输入文本,并将其转换为时间对齐的特征,这些特征表示语音随时间变化的详细特征,例如音调、节奏和语气。常见特征包括:
- 梅尔频谱图,显示声音频率随时间的变化。
- F0 频率,表示音调或基本语音频率。
该系统还会考虑语言学特征,例如某些声音的发音或重音方式,将它们与使语音听起来自然所需的时间对齐。例如,hello 这个词的第一个音很短,第二个音很长。
将时间对齐的特征转换为音频
下一步是将这些特征转换为听起来很逼真的音频。神经网络会处理这些特征以合成流畅自然的声音。先进的文本转语音技术为您提供以下功能:
- 具有耳语功能的音量控制
- 高音和低音
- 快速或慢速
- 多种语言和口音
- 多种说话风格,包括为您的品牌定制的声音和风格。
如何实施文本转语音技术?
组织通过两种方式实施文本转语音技术。
自主管理
AI / ML 团队使用专门的文本转语音 AI 模型,并使用自己的数据对其进行进一步训练。然后,将模型部署到生产环境中,并在各个应用程序中使用。这个过程不但既耗时,而且成本高昂。组织负责维护和管理 AI 模型。使用这种方法可能需要几个月才能获得可用于生产的文本转语音功能。
完全托管
完全托管的文本转语音功能使用第三方模型,您可以使用 API 将其集成到代码中。第三方提供商对模型进行全面的管理、训练和维护。您将文本内容作为输入提供给模型,它会生成音频文件作为输出。您还可以将其设置为将网页和其他动态变化的内容作为输入,并实时生成相应的输出。
完全托管的文本转语音服务经济高效,并且易于使用和集成。无需具备 ML/AI 专业知识即可使用它们。开发人员在几个小时(而不是几天)内即可将这些 AI 语音生成器集成到现有应用程序中。
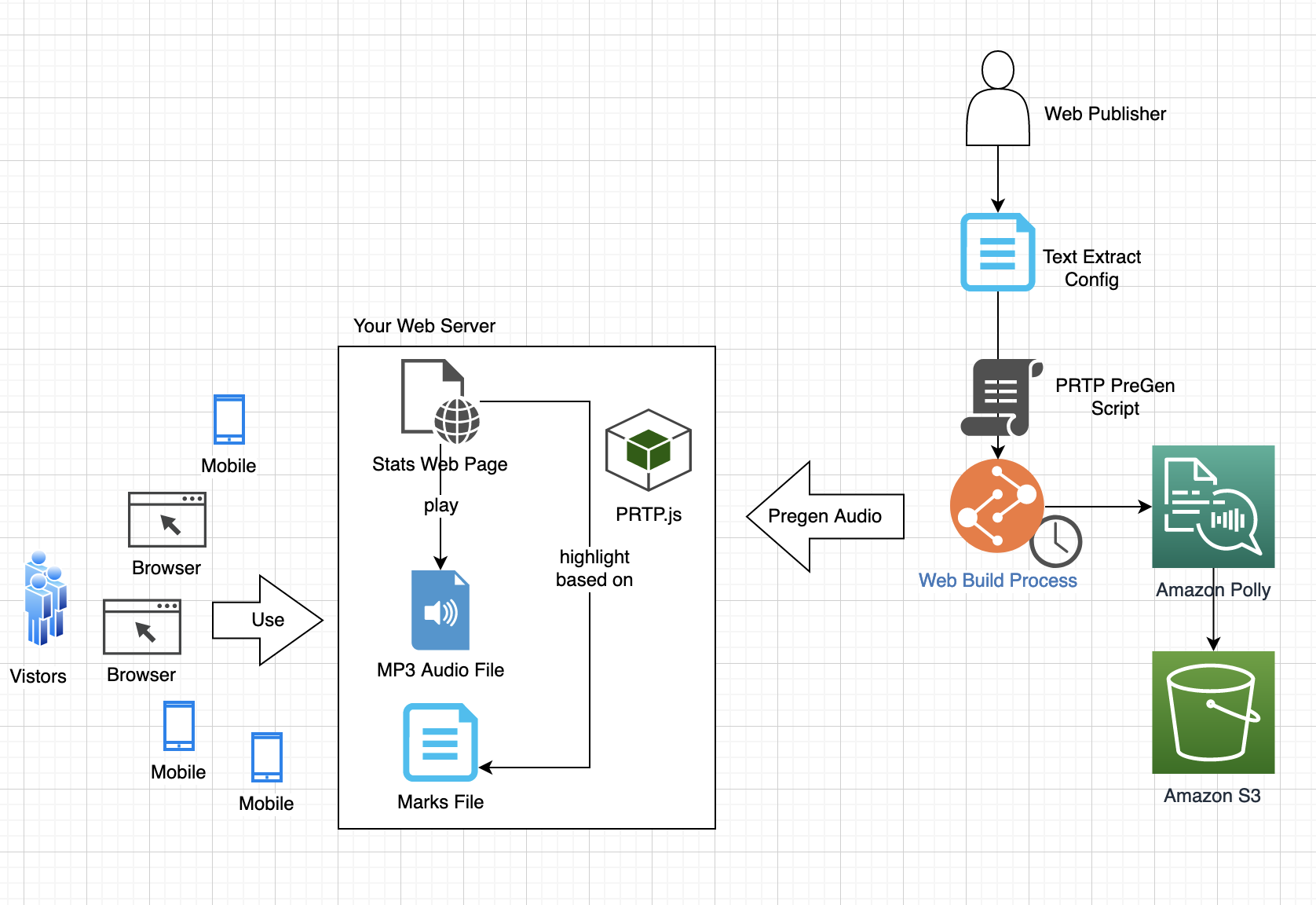
AWS 如何为您的文本转语音项目提供支持?
Amazon Polly 是一项完全托管的服务,可将任何文本转换为逼真的语音。它易于使用,您只需将文本文件发送到 Amazon Polly API,它就会立即返回音频流,直接播放或以标准音频文件格式(例如 MP3)存储。Amazon Polly 采用按实际使用量付费的定价模式、对每个请求收取的费用较低,且对语音输出的重复使用和存储没有太多限制,让您能够经济高效地在任何地方实现语音合成。
例如,使用 Amazon Polly,您可以:
- 将文本转换为数十种逼真的声音和语言的语音,以支持所有类型的用户。
- 根据需要调整输出中的语速、音调或音量。
- 无需额外费用即可缓存和重播生成的语音。
- 高速大规模实施实时文本转语音功能。
您还可以与 Amazon Polly 团队合作,为组织生成合成语音,并通过独特的声音标识让您的品牌脱颖而出。Amazon Polly 已获得 HIPAA(1996 年健康保险流通与责任法案)和支付卡行业数据安全标准(PCI DSS)的认证,可用于受监管的工作负载。
立即 创建免费账户,开始使用 AWS 上的文本转语音功能。